不论是新闻炒作、AI 从业者朋友还是网上的讨论,无不反反复复地在宣告着 AI 时代的重要性,但我却迟迟没有严肃对待这件事。例如,Claude Code 发布已经一年有余,而我也偶尔会用自费的 API 来做一些小程序或分析不熟悉的代码仓库,但我从来没有使用过它做一个真正严肃的项目。是的,LLM 会写一些代码,但这不是我们一直以来都知道的吗?直到最近,看到一些熟识的朋友使用 coding agent 做出了一些相当有趣的东西之后,我才开始第一次严肃地尝试 AI coding。而这次经历对我来说似乎有点过于成功,以至于有些震撼了。这里我想趁着还有些记忆,记录一下我的首个 AI 编码项目的经历。
一个小项目(Cosmobot)和最初的手写阶段
我有很多想尝试的想法,但往往无法以最快的速度落实成可执行的代码。最近因为另一个项目选择了 Haskell 的缘故,我在考虑重新捡起 Haskell 作为「思考的母语」并尝试「精通」它,加上 AI 比较流行,于是我考虑开始做一个 AI agent 来练手。名曰 Cosmobot。
我对这个 AI agent 项目的预期并不高,它只是一个练手项目。因此专门选择了之前没用过的、更 fancy 的技术栈。其中,最核心的两个组件是:
Effectful,或者说一般意义上的 effect 系统,允许将系统的副作用划分成不同的 effect,并允许多个 effect 组合在一起。一种 effect 表达一些特定的能力,如 Log effect 表达写日志的能力,LLM effect 表达调用 LLM 的能力。函数必须明确标记自己可能产生的 effect,如:
mayLog :: (Log :> es) => Eff es ()
mayCallLLM :: (LLM :> es) => Eff es ()
不论是 mayLog 还是 mayCallLLM 都不会直接调用对应的「能力」,而是(不严格地说)「发送一个 effect 请求」,这个请求会被一个 effect 解释器截获,此时才会产生真正的作用。在使用 Effect 系统的项目中,main 往往会有一长串的 runSomeEffect:
main = runEff $
runLog .
runLLM .
runDatabase .
runFile $ do
actualCode
Streaming 则提供了流式数据处理。使用 streaming 处理消息流的初衷也很简单:「消息流」就应该是「流」。不同来源的「流」就应该可以合并到一起,然后统一处理。例如:
incomingMessagesTelegram :: (Telegram :> es, HTTP :> es) => Stream (Of TelegramMessage) (Eff es) ()
incomingMessagesQQ :: (QQ :> es, HTTP :> es) => Stream (Of QQMessage) (Eff es) ()
incomingMessages = incomingMessagesTelegram <> incomingMessagesQQ
基于这样的想法,我实现了一个 Telegram effect,它可以把 getUpdates 转换成 update 流,然后 main 里不断把 update 打印出来。这个项目到此为止就搁置在这里了。
前 6 小时:与 vibe coding 的第一类接触
这个月很巧,ChatGPT 免费送了一个月的 Plus 会员,有一些 Codex 额度。加上看到朋友 vibe coding 做出了不少好玩的东西,于是我也想试一下。
上周六,就用 Cosmobot 项目开刀了。我写了一个简单的 AGENTS.md:
You are a super proficient professional Haskell hacker. You value correctness, conciseness, and above all, performance and robustness of a software system. You have superb taste and you hate messy code. You are a fan of algebraic domain design.
cosmobot is a unified chatbot framework. It is an industrial-grade codebase, but yet is simple enough to be read and modified by humans.
You are granted some autonomy to organize the codebase as you wish.
- Use `effectful` for managing the whole application.
- Use `streaming` for managing incoming messages.
初次使用 AI 编码就让我感到惊讶。Codex 在这个项目上的表现非常出色,总是可以顺利完成我要求的任务,并且效率极高、质量似乎也很不错。
- 它 one-shot 了 QQ 支持给我留下了深刻印象——它似乎对 OneBot API 熟稔于胸,然后轻松用 Haskell 实现了出来。
- 最初为了简便我用了 dotenv 做配置,我让它迁移到 toml,也是直接 one-shot。
- 整个项目只在个位次交互时就推进到了实现了 Telegram 和 QQ 接入、并接入统一消息管线的程度。
到目前为止,我几乎完全没有看代码,只是在不断要求 Codex 增加新功能,而 Codex 也总是能以极快的速度完成任务。更让我惊讶的是,Codex 的实现没有什么问题,以至于我根本不需要去看代码——直接编译、运行,行为就是我想要的。这样快速的反馈循环让我有点上瘾,以至于想不起来 commit 工作进展。最后,居然是已经做完了完整的 agent 工具调用才想起来要 commit。而且 git 中也没有保留「古法编程」的代码,多少有点遗憾。
随着 5 小时额度用完,但我已经完全停不下来了,于是就购买了 40 刀的额度,又续了几个小时的用量。事实上,到前 6 个小时就几乎已经完成了我最初对这个项目的设想:Telegram 和 QQ 支持、工具调用、图像生成与发送、消息解析和保存、简单的权限管理、命令路由。甚至还有一个 saucenao 查图命令,对,也是 Codex 自己实现的,我只提供一个 API key。
中 6 小时:功能、与更多功能
接下来我开始不断增加更多功能:todo 列表、LLM 流式输出、状态管理框架、记忆、web 工具、记忆工具、bash 工具乃至更多工具……到了这时候,额度成了限制我最大的因素,最后耻辱开了 Pro Lite。而整个仓库的代码量也已经达到了惊人的 1 万行。对我来说,以这么点时间完成这么多的功能,多少有点难以置信。
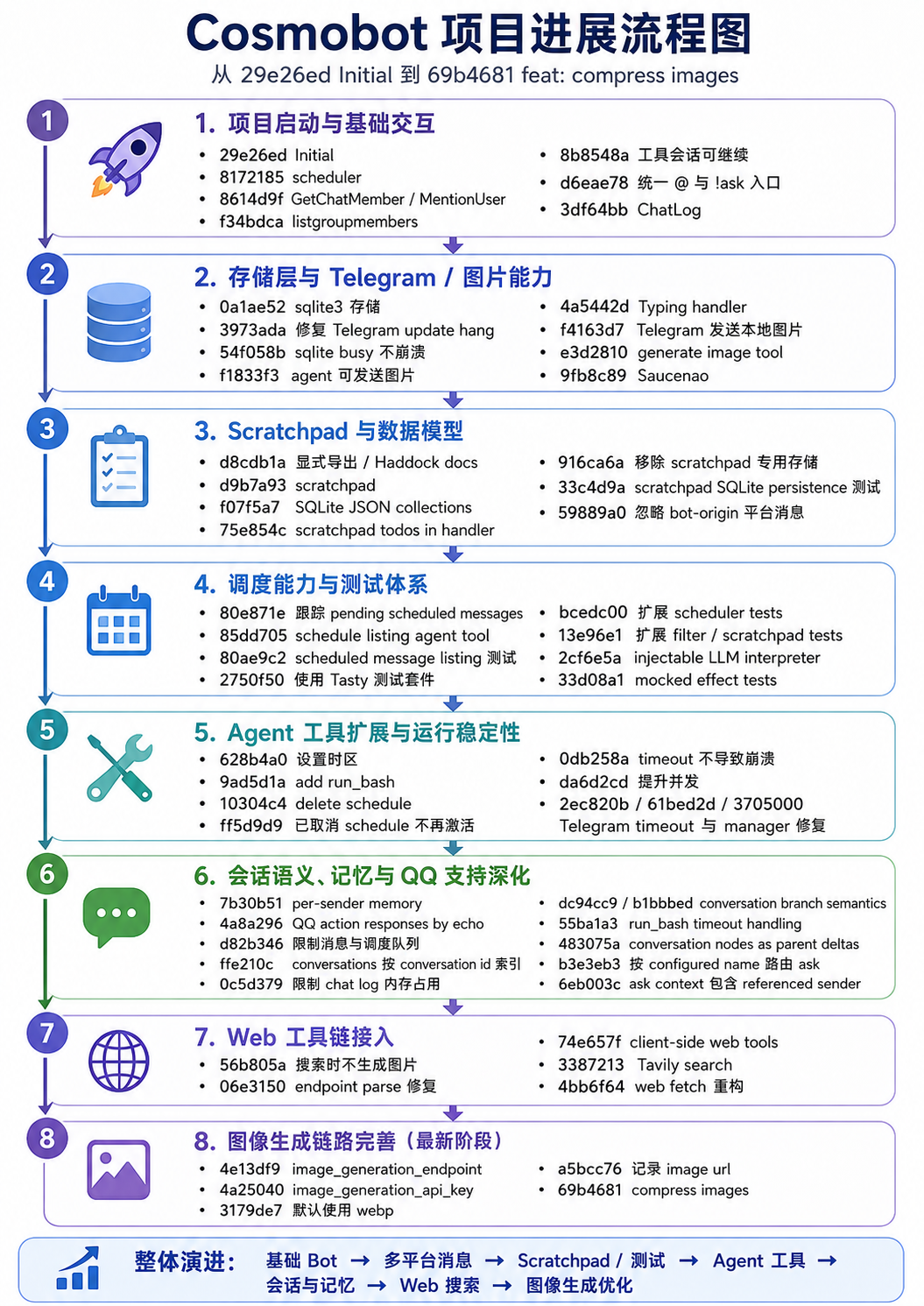
后 6 小时:屎山化与艰难铲屎
此时,整个系统几乎还延续着我最初的架构:AI 只是不断地增加代码、实现功能,而没有考虑如何拆分模块。(当然,我也没有要求它拆分模块。)于是我打算开始整理一下代码。
只是没整理还好,一实际打开代码,就看到整体已经有非常明确的屎山化倾向:
重复不该重复的代码
- 总是不使用已有的库或服务,而是选择手写实现
- 根据消息的平台标签分发具体实现是直接模式匹配实现的,完全不抽象为 type class 或 vtable
- ……
耦合不该耦合的代码
- Main 模块里存在合并并发流的代码
- LLM 模块中存在 HTTP 代码
- Agent 模块中存在大量 tools
- Conversation 数据结构与 Conversation 的混在一起
- 所有 SQLite 状态全部集中在一个模块里
- ……
而且 Codex 的倾向是直接在原地改动代码,而不是思考有没有更合适的抽象。例如,原本 Agent 循环的代码是这样的:
runAgent
:: (LLM.LLM :> es, Log :> es)
=> Int
-> AgentContext es
-> [Tool es]
-> Conversation
-> Eff es (Text, Conversation)
runAgent maxTurns context tools conversation =
loop (max 1 maxTurns) (closeInterruptedToolCalls conversation)
where
exposedTools = filter (`toolAllowed` context) tools
loop turnsLeft current = do
answer <- LLM.askWithTools (map toolSchema exposedTools) current.messages
let answered = appendMessage (LLM.assistantAnswer answer) current
case answer.toolCalls of
[] ->
pure (answer.content, answered)
calls
| turnsLeft <= 1 -> do
logInfo "Agent tool turn limit reached" calls
let paused = appendMessages (map pausedToolResult calls) answered
pure (toolLimitMessage answer.content calls, paused)
| otherwise -> do
results <- traverse execute calls
let next = appendMessages (map fst results) answered
traverse_ (\messageId -> context.remember messageId next) (concatMap snd results)
loop (turnsLeft - 1) next
execute call = do
let callName = call.name
result <- runTool context tools call `catch` \(err :: SomeException) ->
pure (toolText [i|Tool #{callName} failed: #{show err :: String}|])
pure (LLM.toolResult call result.content, result.messageIds)
接着,Codex 在某次变更中将这个原本不太糟糕的函数改成了相当糟糕的实现:把 web fetch 的状态直接塞进了算法核心。更糟糕的是,我发现这一点相当晚,因为这是疯狂堆功能阶段改的,那时候我还不怎么看代码。
runAgent
:: (LLM.LLM :> es, Log :> es)
=> Int
-> AgentContext es
-> [Tool es]
-> Conversation
-> Eff es (Text, Conversation)
runAgent maxTurns context tools conversation =
loop (max 1 maxTurns) 0 (closeInterruptedToolCalls conversation)
where
exposedTools = filter (`toolAllowed` context) tools
loop turnsLeft webFetchUses current = do
answer <- LLM.askWithTools (map toolSchema exposedTools) current.messages
let answered = appendMessage (LLM.assistantAnswer answer) current
case answer.toolCalls of
[] ->
pure (answer.content, answered)
calls
| turnsLeft <= 1 -> do
logInfo "Agent tool turn limit reached" calls
let paused = appendMessages (map pausedToolResult calls) answered
pure (toolLimitMessage answer.content calls, paused)
| otherwise -> do
(results, nextWebFetchUses) <- executeCalls webFetchUses calls
let next = appendMessages (map fst results) answered
traverse_ (\messageId -> context.remember messageId next) (concatMap snd results)
loop (turnsLeft - 1) nextWebFetchUses next
executeCalls webFetchUses [] =
pure ([], webFetchUses)
executeCalls webFetchUses (call : calls) = do
(result, nextWebFetchUses) <- execute webFetchUses call
(rest, finalWebFetchUses) <- executeCalls nextWebFetchUses calls
pure (result : rest, finalWebFetchUses)
execute webFetchUses call = do
let callName = call.name
webFetchCall = callName == "web_fetch"
webFetchLimit = context.toolConfig.webFetchMaxUses
result <-
if webFetchCall && maybe False (webFetchUses >=) webFetchLimit
then pure (toolText [i|web_fetch use limit reached for this agent run: #{webFetchUses}.|])
else runTool context tools call `catch` \(err :: SomeException) ->
pure (toolText [i|Tool #{callName} failed: #{show err :: String}|])
let nextWebFetchUses =
if webFetchCall && maybe True (webFetchUses <) webFetchLimit
then webFetchUses + 1
else webFetchUses
pure ((LLM.toolResult call result.content, result.messageIds), nextWebFetchUses)
(这个重构的要点是:每次 agent turn 里 tool 可以有自己独立的状态,但如何把这个机制做得可扩展?)

直到这时我才意识到,问题越来越多了,必须要尽快铲屎,否则会严重影响未来的变更。不管是人写还是 AI 写,这样的代码都会是灾难。
于是这段时间,基本上一直在重构代码。更让我意外的是,AI 之前快速堆功能阶段引入的技术债并不止一点半点。
我首先要求 Codex 根据代码生成信息更丰富的 AGENTS.md。但让我非常惊讶的是,尽管 Codex 自己写了全部的代码,它本身似乎对整个数据流依然不够理解。不论我如何让它生成 AGENTS.md,甚至我已经反复指导它数据流到底是怎样的,它依然会写出很多错误来。最后,我不得不亲自改动一些文字,让 Codex 扩写,才得到了正确的系统架构描述。也就是现在的版本:
Data enters through a concrete chat driver, is normalized into `IncomingMessage`, and passes through route admission. If no route matches, the message is ignored. If a route matches, it enters a handler for user-facing behavior.
Handlers do not provide real capabilities themselves. A handler applies command or conversation policy, then calls effects such as `Chat`, `LLM`, `Scheduler`, `AgentTrace`, or chat-log effects. Effect interpreters provide the concrete capability: they may call platform APIs, run LLM requests, use `IOE`, or read/write through Storage or Memory systems.
Keep this direction of dependency intact:
platform event -> core message -> route -> optional handler -> effects -> concrete capability
When a handler invokes the agent path, the nested flow is:
handler -> LLM effect -> agent loop -> LLM transport -> optional tool calls -> agent trace -> agent result -> handler reply
在这段时间内,我不断要求 Codex 做一些结构上的变更,最后才逐渐把一些耦合在一起的模块拆开。我还要求 Codex 审读自己的代码,并指出可能的性能问题、内存泄漏问题,并让 Codex 自行修复。
末 6 小时:更进一步地架构优化
做完了基本的模块调整后,我开始人工审读一些代码。看了一些代码之后才意识到,问题比我想象中更多。举例来说:
main :: IO ()
main = do
...
runEff $
runBotLog cfg.logLevel .
ChatLog.runChatLog maybeSQLiteStore .
Memory.runMemory cfg.memory .
Scheduler.runScheduler $
LLM.runLLM cfg.llm $
ChatDriver.runChatDrivers cfg.qq cfg.telegram cfg.matrix \chatMessageStreams -> do
...
这个代码让我非常奇怪。因为它完全可以写成更美观的形式:
main :: IO ()
main = do
...
runEff $
runBotLog cfg.logLevel .
ChatLog.runChatLog maybeSQLiteStore .
Memory.runMemory cfg.memory .
Scheduler.runScheduler .
LLM.runLLM cfg.llm .
ChatDriver.runChatDrivers cfg.qq cfg.telegram cfg.matrix $ do
...
也是从这里开始,我偶尔会手动调整代码了。
最近做的,且最难的一个重构是 Agent 循环的重构。虽然之前给 Agent 增加审计日志也是 one-shot 的,但 AI 的实现我非常不满意:
agentLoop agentRun agentState = do
...
lift $ AgentTrace.recordEvent (modelTurnFinished agentRun.runId agentState.turn answer)
...
case answer of
LLM.ChatFinalAnswer{content} ->
lift (recordAgentFinished agentRun.runId "answered" content agentState.turn) *>
...
LLM.ChatToolRequest{content, toolCalls} ->
...
这个设计过于命令式,难以阅读也难以维护:到底哪里应该记录 trace?中间抛异常了怎么办? 而 Haskell 中的 bracket 模式安全且易读,于是我想将整个 trace 机制重构为 bracket 模式。但同时,看着这段代码,我又在想,这个代码非常复杂,很难看懂,有没有办法让 agent 循环变得非常 generic 以至于其核心可以一眼看懂?(以前我看过 Semantic 的代码,它的核心其实是一个高度抽象的 definitional interpreter,在上面叠加东西后就可以实现不同的 abstract interpreter。受到 semantic 启发,我怀疑这里也可以。)但我又实在没什么想法,于是就不断尝试用各种关键字让 Codex 想不同设计。这个过程真的非常折磨。事实上,Codex 给出的解法,每个都可以用,但就是感觉不够优雅,全部被我否决掉。
(这个重构的要点是:如何把观测从 agent 的逻辑里完全拆出来?)
最后 Codex 想到了显式状态机,而我想到状态机可以用互递归函数实现,用这个关键字提醒了它后,它终于给出了一个我满意的实现。再经过一段时间的拆分和修整(如何设计一种可扩展的机制,使得各种中间件(如观测)可以随意挂在 agent 逻辑里?),最终得到了一个我相当满意的结果:
runAgentLoop
:: AgentProgram es
-> ModelTurn es
-> ToolTurn es
-> AgentState
-> Stream (Of Text) (Eff es) AgentCompletion
runAgentLoop program modelTurn toolTurn agentState = do
program.aroundModelTurn agentState (modelTurn agentState) >>= \case
ModelAnswered completion ->
pure completion
ModelNeedsTools toolState -> do
continuedState <- lift (toolTurn toolState)
runAgentLoop program modelTurn toolTurn continuedState
整个 agent 循环的核心被寥寥数行完全描述。并且它是一个纯算法,因为它不依赖于任何 effect!在这个基础上,可以通过 aroundModelTurn 等机制叠加不同的中间件:
defaultAgentProgram :: (Log :> es, IOE :> es) => AgentObserver es -> Int -> AgentRun es -> AgentProgram es
defaultAgentProgram observer maxTurns agentRun =
emptyAgentProgram agentRun
& withToolFailureRecovery
& withToolLimit maxTurns
& withObservation observer
未来如果要增加上下文压缩等机制,只需要在这里增加一行即可。这项重构耗时很久:Codex 不断提出新的想法,而我不断否决,最后 Codex 提出一些想法,我也提出一些想法,合起来才得到了一个最好的结果。
在完成了 Agent 重构后,我又进一步重构了组件状态管理,让组件自己的状态在自己的模块中定义。同样地,我不再盲目接受 Codex 给的代码,而是反复让 Codex 返工,最终才得到我满意的结果。
一些感受
截至目前,用 Codex 在这个项目上花了恰好大概 24 小时,平均一天 6 小时:
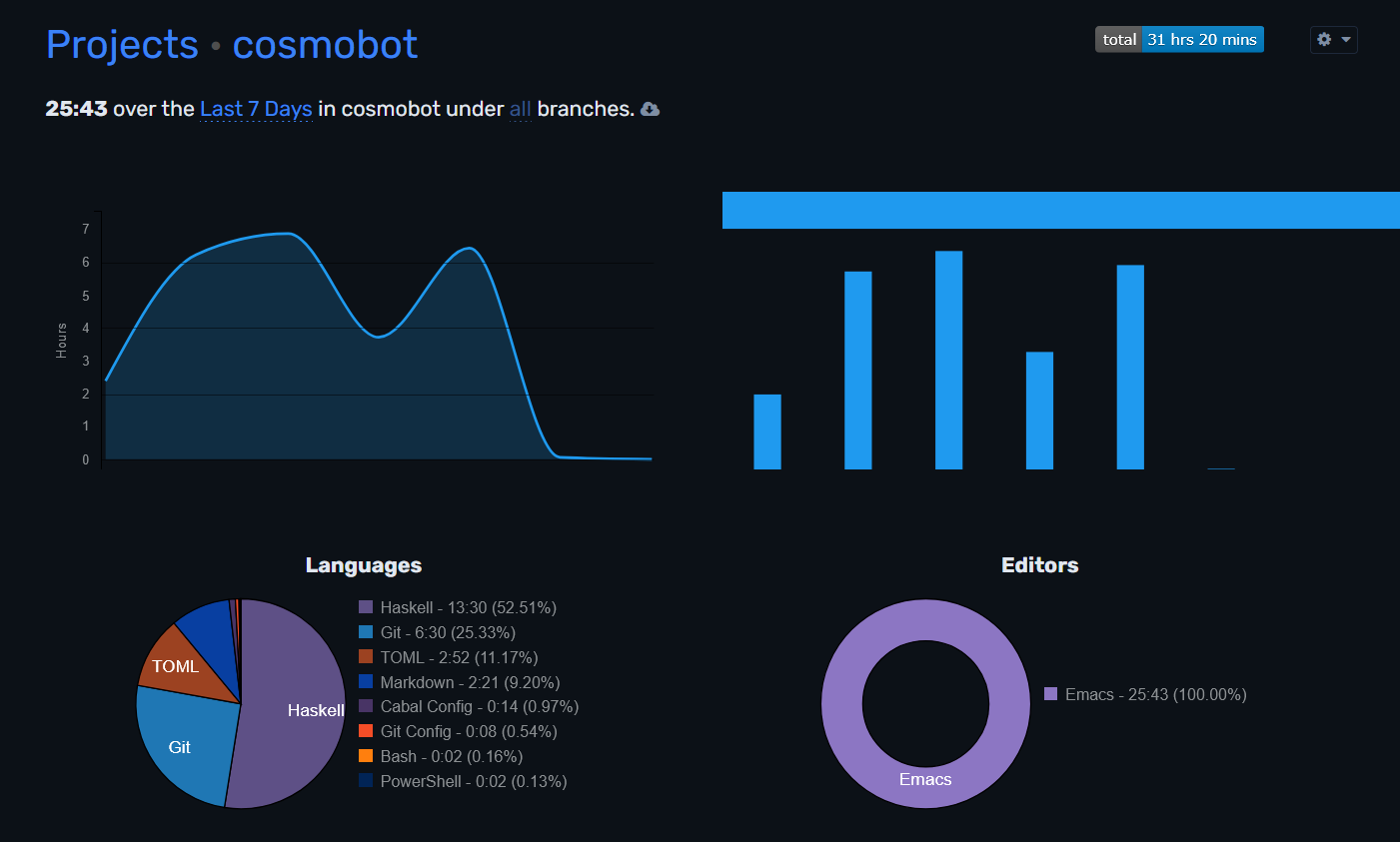
从前两天的 vibe coding,到中间两天的铲屎和 code review,我觉得我从对 vibe coding 上瘾到祛魅也可以说是相当快了。
- 只计算编写的代码行数,如果不看代码,我认为 Codex 产出代码的速度是我的 16 倍。但如果考虑到 review,我觉得差距可能就快速下降到 8 倍,再算上不停返工可能还会更低。也许我应该放更多的手?当然,根据项目性质,有些项目的确可以完全放手,那就可以完全享受到 AI 带来的快感。
- 一旦需要人去 review 代码,反而觉得比自己写代码更心累。毕竟写代码还是比较放空大脑的。
- 用 AI 重构项目的速度非常快,因此可以大胆尝试多种不同设计,然后选出最好的。
- Codex 似乎不太会反驳用户,用户的想法,无论好还是坏,都会直接执行。因此,有些复杂的任务我会写比较长的 prompt 来指导他如何做。比如我尝试过把 streaming 迁移到 streamly(另一个 Haskell 流式数据处理库),prompt 长达 1000 多字符。
- 可能最重要的收获:即使几乎不手动编码,也可以用 AI 可以做出靠谱的项目。在 1 万 2 千行的 Cosmobot 中,我手写的代码可能还不到 10%(考虑到最初的手写)。
那么,实验成功了吗?
我认为是相当成功的。对我来说,在 4 天内产出 1 万多行可用的 Haskell 代码,并且代码质量还不错,哪怕在上周的我看来都是难以想象的。因此,我估计我以后会越来越多地使用 AI 来辅助编码了。但依据项目类型,可能依然需要人工参与。特别是一些较大型的、需要长期演化的项目,更需要人工在核心的、需要扩展性的地方严格把关。
此外,我认为项目成功还有一个要素是因为大部分功能全部都是 one-shot 出来的,而且直接就可以用。即使有问题,我自己也完全不调试:只要把日志贴进 Codex,它就可以 one-shot 修复好。我有一些猜想:
- 最初功能可以 one-shot 而不出大问题,有两个原因:
- 我已经提前规定好了系统的形状,LLM 可以直接填空
- 很多功能 LLM 已经很熟悉,可以直接背诵
- 更大规模的变更 one-shot 而不出大问题、甚至不用调试,Haskell 本身的特性也很重要。
- 在 Haskell 里,LLM 完全不会 defensive programming。几乎所有代码都是有效逻辑。
- 代码非常简短,搭配合适的抽象,代码逻辑一目了然,即使所有代码都 review,负担也不算太重。在 Cosmobot 项目中,我 review 的最大的一次功能变更也才 1000 行左右。
- 此外,由于 Haskell 对各种 effect 的管理很严格,review 往往只需要看类型而不需要看实现。
- 不断重构让架构保持干净的意义是让更多功能可以 one-shot。
- AI 善于模仿已有 pattern;如果没有可模仿的,就容易直接就地把代码加到最容易快速实现的地方。
- 重构出可以横向扩展的地方,AI 就可以轻松填空,即使局部写出屎山,也不影响其他地方。
因为这是我第一个严肃的 AI coding 项目,所以这些猜想目前只能是猜想。但由于 Haskell + AI 体验是如此之好,我未来可能也会首选 Haskell 来做 AI coding。
Say hi to Cosmobot
由于不管什么功能都可以 one-shot 实现,我现在已经开始让 Cosmobot 自己给自己加功能了(为什么标点这么乱?因为都是复制出来的实际 prompt,都是 one-shot 实现):
- 打开你自己的源代码,给 Admin Handler 里加个 !ping 命令,收到之后输出 pong,加完之后自己编译并重启
- 模拟这个图的信息和格式,在 Admin Handler 里加一个 !vt 命令,输出相同的图片。参考 Typing handler,你应该使用 typst 生成图片。做完之后自己编译并重启,但要先通知我一声。
- 这是个机器人消息, 自动触发很烦, 你自己加个 ShutUp Handler, 在QQ群里每次看到这个消息就自动撤回, QQ driver和Chat effect里加入delete message接口, 做完告诉我我给你管理员权限
- 看一下你自己的源代码(用bash工具), 然后根据你对自己源代码的印象, 给你自己设计个二次元看板娘形象, 然后生成图片

于是下一步想逐渐把它扩展成一个 coding agent,毕竟……「自举」这件事真是太好玩啦!